
Profile Guided Optimization (PGO) 初探 [Clang 篇]
前言
上一篇我们看了 GCC 的 PGO,是时候来看看 Clang 啦!
源程序和编译参数都和 GCC 的一样,clang 的 wrapper 做的还是很好的!
clang version 10.0.0-4ubuntu1
Target: x86_64-pc-linux-gnu
Thread model: posix看一下段
话不多说,我们直接 IDA 启动:

可以发现,多了几个段,顾名思义即可。相比之下,GCC 就不会多出来段,全部都混在一起非常难搞。
参考 Clang文档 ,看一下每个段的数据:
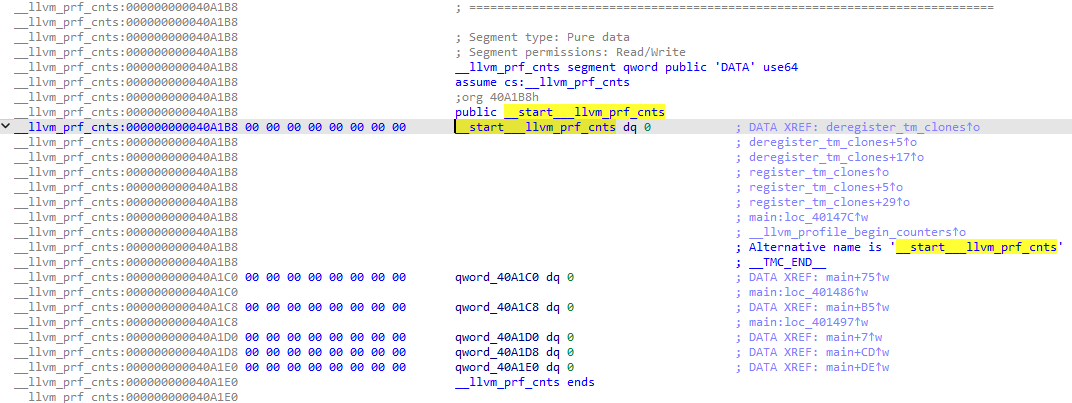
__llvm_prf_cnts 这个段就全部都是计数器。
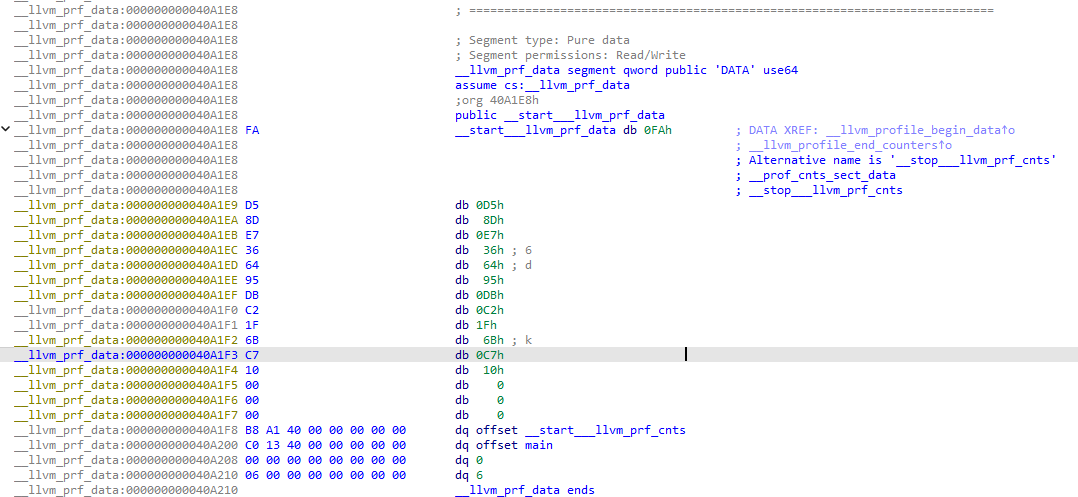
__llvm_prf_data 这个段主要是一些元数据。多编译一个单元,可以得到更多一份,这样就有规律可循:
#include <stdio.h>
void mm(){
puts("BBB");
}
void m(){ puts("CC");}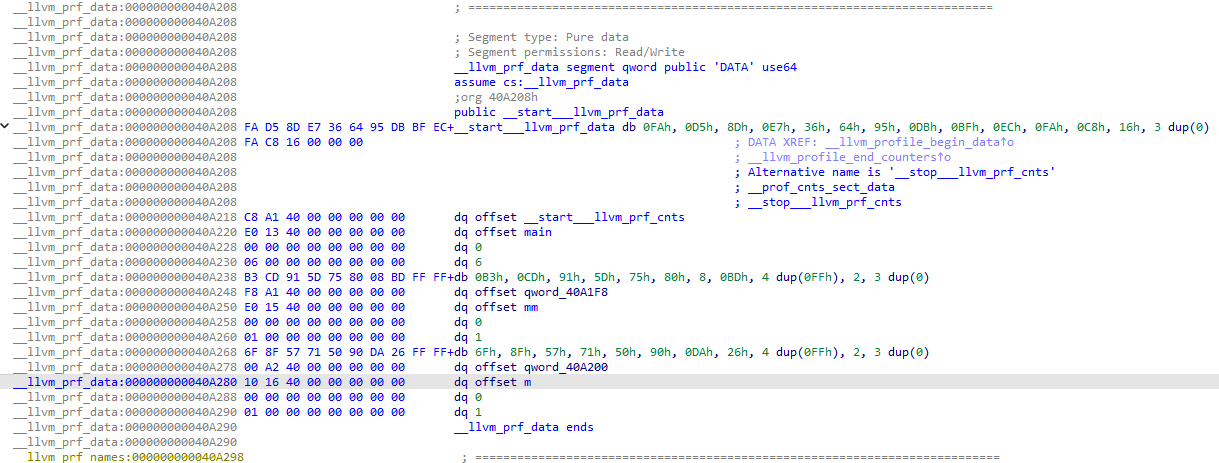
可以知道每个函数对应一个块,每个块具有如下结构:
struct meta_t {
char header[12];
uint32_t some_nums; // 和函数行数有关
void* ptr_to_cnt_start;
void* func;
void* reserved;
uint64_t num_cnts;
};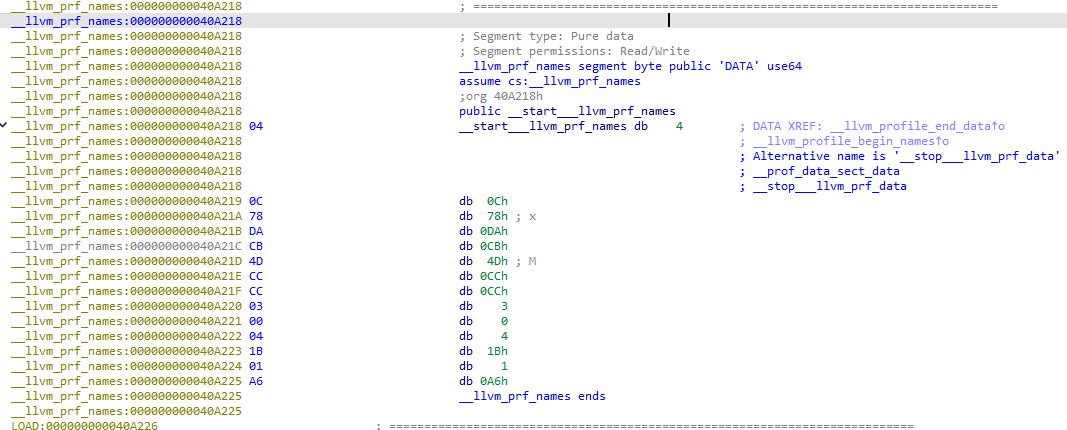
__llvm_prf_names这个段主要提供了名称信息,在实际的 profdata 中通常是被复制写入的。
根据文档的意思,数据是 zlib 压缩的,我们用 CyberChef 梭一下:
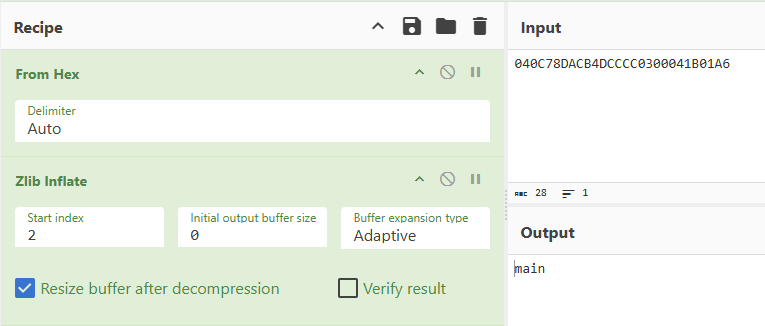
可以看到是存储了函数名称。
另外注意到其后有一个 LOAD 段,这只是个 padding,不需要考虑。
然后是 __llvm_prf_vnds 这个段,全部都是 0,长度是 0x6000,即便多编译单元其长度也不变,暂不明确用途。
反编译
int __cdecl main(int argc, const char **argv, const char **envp)
{
int v3; // ebx
__int64 v4; // rsi
__int64 v5; // rcx
__int64 v6; // rcx
++qword_40A1D0;
v3 = strtol(argv[1], 0LL, 10);
if ( (int)strtol(argv[2], 0LL, 10) <= 0 )
{
if ( v3 >= 3 )
{
v4 = 2LL;
v6 = 0LL;
while ( v3 % (int)v4 )
{
v4 = (unsigned int)(v4 + 1);
if ( -(__int64)(unsigned int)(v3 - 2) == --v6 )
{
qword_40A1C8 += (unsigned int)(v3 - 3) + 1LL;
goto LABEL_12;
}
}
qword_40A1C8 -= v6;
++qword_40A1E0;
goto LABEL_15;
}
LABEL_12:
++_start___llvm_prf_cnts;
}
else if ( v3 >= 3 )
{
v4 = 2LL;
v5 = 0LL;
while ( v3 % (int)v4 )
{
v4 = (unsigned int)(v4 + 1);
if ( -(__int64)(unsigned int)(v3 - 2) == --v5 )
{
qword_40A1C0 += (unsigned int)(v3 - 3) + 1LL;
return 0;
}
}
qword_40A1C0 -= v5;
++qword_40A1D8;
LABEL_15:
printf("%i", v4);
}
return 0;
}int __cdecl main(int argc, const char **argv, const char **envp)
{
int v3; // ebx
__int64 v4; // rsi
v3 = atoi(argv[1]);
if ( atoi(argv[2]) <= 0 )
{
if ( v3 >= 3 )
{
v4 = 2LL;
while ( v3 % (int)v4 )
{
v4 = (unsigned int)(v4 + 1);
if ( v3 == (_DWORD)v4 )
return 0;
}
goto LABEL_12;
}
}
else if ( v3 >= 3 )
{
v4 = 2LL;
while ( v3 % (int)v4 )
{
v4 = (unsigned int)(v4 + 1);
if ( v3 == (_DWORD)v4 )
return 0;
}
LABEL_12:
printf("%i", v4);
}
return 0;
}不难发现 clang 的默认优化都比 GCC 要激进一些。对比起来,Clang 没有生成关于间接调用追踪的代码,函数体内的插桩全部都是简单的加减法;而且插桩倾向于在基本块靠后的位置。插桩后似乎又进行了一次优化才生成的机器码,导致看起来稍显费劲。
测试和调优
还是按照 GCC 篇中的办法,使用 10201 1 参数运行一次,得到一个名字很长的文件:
-rwxrwxrwx 1 wsl wsl 192 Apr 6 11:03 default_15822678452419286522_0.profraw这个是原始文件,要用它来调优,我们还需要做格式转换。
llvm-profdata-10 merge -o=default.profdata default_15822678452419286522_0.profraw这将从原始数据合并出来一个 default.profdata 供 Clang PGO 优化使用。
随后,
clang -Og -fprofile-use test.c -o test_clang_pguse得到优化后的程序。
很不幸的是,我们并没有观测到任何的变化,反编译的代码仍然是:
int __cdecl main(int argc, const char **argv, const char **envp)
{
int v3; // ebx
__int64 v4; // rsi
v3 = strtol(argv[1], 0LL, 10);
if ( (int)strtol(argv[2], 0LL, 10) <= 0 )
{
if ( v3 >= 3 )
{
v4 = 2LL;
while ( v3 % (int)v4 )
{
v4 = (unsigned int)(v4 + 1);
if ( v3 == (_DWORD)v4 )
return 0;
}
goto LABEL_12;
}
}
else if ( v3 >= 3 )
{
v4 = 2LL;
while ( v3 % (int)v4 )
{
v4 = (unsigned int)(v4 + 1);
if ( v3 == (_DWORD)v4 )
return 0;
}
LABEL_12:
printf("%i", v4);
}
return 0;
}即使我们重新以 -O3 编译也一样无法起效。看来,Clang 的默认优化就已经做的很好?
挺无奈的。。。