
AbydOS开发日记 (6) - 多核初步
多核与多线程
一个 CPU 上可能不止一个核心 (Hart),这些核心在物理上分开,独立运行,但是共享总线和外设。也就是说,它们的物理内存空间是一致的,只不过有自己单独的寄存器和 Cache、MMU。而多线程非常类似,只不过是通过调度的方式实现,将多个线程的寄存器等资源分时复用。在裸机的角度上看,我们可以把多核看成硬件的多线程,并利用类似的技术实现。
核心的启动
在 RISCV 手册中,并没有规定 Hart 的启动顺序。比较通常的做法是,核心全部(近乎)同时从 M-mode 启动,随后 SBI 会通过原子量确定一个启动核心,并且执行初始化。至于 S-mode 中是否同时启动,我并没有明确看到文档指出,所以应该也是 SBI 实现自定义。通过实验,OpenSBI 只会将启动核心带入到 S-mode,其他核心会留在 M-mode 等待。但是,我们仍然有必要通过一个原子量保证 S-mode 初期只有一个核心运行,具体看,就是下面的汇编代码:
_start:
/* Pick one hart to run the main boot sequence */
lla a3, _hart_lottery
li a2, 1
amoadd.w a3, a2, (a3)
bnez a3, _start_hang // in case multi core start at the same time这些代码在入口点立即执行,如果有多个核心,没有抢到控制权的就会跳到 _start_hang 的死循环里。当然,为了兼容性,后面肯定会设置一下中断再睡觉,不然在其他 SBI 上可能没法用。
那么我们如何通过 SBI 启动核心呢?答案是 SBI 的 HSM 扩展,即 Hart State Management。该扩展提供 4 个 ecall 调用,分别对应核心的 启动、(自)停止、状态查询和暂停。如下:
struct sbiret sbi_hart_start(unsigned long hartid,
unsigned long start_addr,
unsigned long opaque);
struct sbiret sbi_hart_stop(void);
struct sbiret sbi_hart_get_status(unsigned long hartid);
struct sbiret sbi_hart_suspend(uint32_t suspend_type,
unsigned long resume_addr,
unsigned long opaque);文档说明,可以通过 sbi_hart_start 从指定的 start_addr 启动核心,并且其 a0 = hartid,a1 = opaque。
核心的初始化
基于之前的布局,确定启动其他核心的时机是设备外设驱动安装完成后。此时内存映射和系统栈已经确定,可以确定下一步的所有数据。启动后,执行环境非常原始,需要一点汇编来做初始化工作。
启动流程
- 汇编初始化C环境
- k_early_boot() 初始化 C++ 环境
- k_boot() 探测并安装系统设备,开启 MMU,从系统堆分配并映射系统栈区
- 返回汇编,设置系统栈,进入 k_boot_perip()
- k_boot_perip() 探测并安装外设,初始化系统输入输出等
- 返回汇编,设置启动核心栈,带入 k_boot_harts()
- k_boot_harts() 调 SBI 启动其他核心
- 被启动核心初始化 MMU 和栈等,再进入 C++ 初始化执行环境,等待系统状态切换
- 全部启动完成,进入多核模式
内存映射
核心启动后,其 SATP = 0 和 sstatus.SIE = 0,即 MMU 和中断是关闭的。我们的系统栈是布置在虚拟地址空间的,所以要先启用 MMU。在之前的启动步骤,我们保存了系统 MMU 配置寄存器 (SATP) 的值,我们将在所有核心上使用同样的映射。所以内存映射非常简单,只需将保存的值写入 satp 后,刷新 TLB 即可:
_start_hart:
/* a0: hartid a1: reserved */
lla a2, _sys_satp
REG_L a2, 0(a2)
csrw CSR_SATP, a2
sfence.vma zero, zero核心系统栈的设定
在前面的步骤,我们确定了系统栈的空间,这里要根据 hart id,通过简单的乘法得到核心系统栈基址。如下:
/* Setup system stack base according to hart_id as offset */
lla a3, _sys_stack_base
REG_L sp, 0(a3)
li a2, K_CONFIG_STACK_SIZE
mul a3, a0, a2
sub sp, sp, a3理论上,这里开始就可以进入 C++ 了,但是不要忘记一件事,就是 libc 的上下文还没解决。
多核下 Newlib 的上下文
可重入函数
在 newlib 中,几乎所有函数都提供了两个版本,即不可重入的普通版本(ANSI),以及可重入的版本。不可重入的版本,其最终还是调用了可重入版本的函数,不过传入了一个全局重入结构。例如,printf:
不可重入版:
int printf (const char *__restrict, ...)
_ATTRIBUTE ((__format__ (__printf__, 1, 2)));可重入版:
int _printf_r (struct _reent *, const char *__restrict, ...)
_ATTRIBUTE ((__format__ (__printf__, 2, 3)));可以注意到,可重入版本多了一个 _reent 结构体,其在 <sys/reent.h> 定义,一并定义了全局的:
/*
* All references to struct _reent are via this pointer.
* Internally, newlib routines that need to reference it should use _REENT.
*/
#ifndef __ATTRIBUTE_IMPURE_PTR__
#define __ATTRIBUTE_IMPURE_PTR__
#endif
extern struct _reent *_impure_ptr __ATTRIBUTE_IMPURE_PTR__;
#ifndef __ATTRIBUTE_IMPURE_DATA__
#define __ATTRIBUTE_IMPURE_DATA__
#endif
extern struct _reent _impure_data __ATTRIBUTE_IMPURE_DATA__;
/* #define _REENT_ONLY define this to get only reentrant routines */
#if defined(__DYNAMIC_REENT__) && !defined(__SINGLE_THREAD__)
#ifndef __getreent
struct _reent * __getreent (void);
#endif
# define _REENT (__getreent())
#else /* __SINGLE_THREAD__ || !__DYNAMIC_REENT__ */
# define _REENT _impure_ptr
#endif /* __SINGLE_THREAD__ || !__DYNAMIC_REENT__ */
#define _REENT_IS_NULL(_ptr) ((_ptr) == NULL)
#define _GLOBAL_REENT (&_impure_data)在 newlib 内部,不可重入函数通过 _REENT 宏获取全局重入对象指针后传入可重入版本,完成后续操作。
提供核心本地的 _reent
从上面的定义可以看出,我们如果以 __DYNAMIC_REENT__ 定义的情况编译 newlib,那么就可以通过 __getreent() 函数,提供核心本地的 _reent 结构。稍微修改编译脚本,重新编译工具链(参见此处),然后添加一个实现:
struct _reent *__getreent(void)
{
if (k_stage == K_MULTICORE)
return &hl_reent;
return _GLOBAL_REENT;
}这里 hl_reent 是线程本地 (Hart Local) 的 _reent。
读到这里,很容易想到一个问题,那就是我的 hl_reent 如何存储呢?
核心本地存储
核心本地存储,就是每个核心所单独享有的存储空间。在不同核心上运行的系统程序,应该具有同样的需求,(代码都一样啊),即我们需要通过一些手段来区分核心并从不同的地方提供存储。
原始方法
一个简单而容易想到的方法是,不使用统一的 MMU 映射,而是通过差别映射,将核心系统栈固定在一个地址,然后在核心栈以上预留一段空间,作为核心本地存储。具体实现,可以参考此提交时的仓库。
获取地址的函数示例:
void *k_getHartLocal()
{
extern uintptr_t _sys_stack_base;
extern char _KERNEL_HART_LOCAL_DATA_SIZE;
return (void *)(_sys_stack_base - (uintptr_t)&_KERNEL_HART_LOCAL_DATA_SIZE);
}改进方案:利用 TLS
前面说过,多核可以看成硬件实现的多线程,那就可以利用一下多线程的技术。这里的 TLS 不是 计网的 TLS,而是 Thread Local Storage。其具体定义可以参考 ELF Handling For Thread-Local Storage。
简单来说,通过 C++ 的 thread_local 关键字,或者 C 中的 _Thread_local 定义的变量,会被编译器放入特别的段:.tbss 和 .tdata。这些段并不是直接拿来用的,而是作为一个副本,由实现自行加载内存区域并初始化。那么,如何寻址呢?在 RISCV 上,静态链接的情况下,是通过 tp 寄存器。该寄存器持有一个基址,即 TLS 本地存储的最低地址。我们要做的,首先是创建这两个段,拿到其原始数据的地址:
.tdata :
{
PROVIDE(_tdata_start = .);
*(.tdata)
*(.tdata.*)
. = ALIGN(8);
PROVIDE(_tdata_end = .);
}
/* In TLS, do not add align 4K, otherwise addressing to tbss will need to add a 4k from $tp which cost much space */
.tbss : {
PROVIDE(_tbss_start = .);
*(.tbss)
*(.tbss.*)
. = ALIGN(8);
PROVIDE(_tbss_end = .);
}要注意的是,由于依赖 tp 寻址,所以两个段中间的空闲区域也会算进去,应该不加对齐,否则会浪费内存,搞不好就非法访问了。(我才不会告诉你我调了一上午才发现 qwq)。
然后,在核心初始化时基于核心栈底,保留一段空间作为 TLS ,设置好 tp 寄存器通过汇编实现:
/* Reserve Exception stack */
li a3, K_CONFIG_EXCEPTION_BACKUP_SIZE
csrw CSR_SSCRATCH, sp
sub sp, sp, a3
_process_tbss:
/* Setup tbss */
lla a4, _tbss_start
lla a5, _tbss_end
beq a4, a5, _process_tdata
sub a2, a5, a4
sub sp, sp, a2
mv tp, sp
mv a3, tp
/* Zero-out tbss */
_tbss_zero:
REG_S zero, (a3)
add a3, a3, __SIZEOF_POINTER__
add a4, a4, __SIZEOF_POINTER__
blt a4, a5, _tbss_zero
_process_tdata:
/* Setup tdata */
lla a3, _tdata_start
lla a2, _tdata_end
beq a3, a2, _fini_setup_hart
sub a2, a2, a3
sub sp, sp, a2
mv tp, sp
/* Copy tdata */
lla a4, _tdata_end
mv a5, tp
_tdata_copy:
REG_L a2, (a3)
REG_S a2, (a5)
add a3, a3, __SIZEOF_POINTER__
add a5, a5, __SIZEOF_POINTER__
blt a3, a4, _tdata_copy
_fini_setup_hart:
ret这里顺便预留一下异常处理空间。处理完成后,整个布局如下:
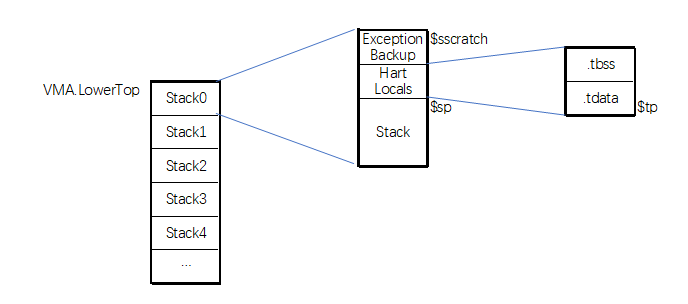
TLS 支持的 newlib
NewLib 本身可以使用 TLS 来替代 _reent,但是我目前没有采用这种方案,原因是,
- 在启动早期的单核阶段,TLS 需要额外的空间分配和复制,比较难以实现
- 在系统退出多核模式后,还要重新初始化 TLS,避免死锁和冲突
多核同步
进入多核模式
由于核心启动需要时间,而我们不希望在所有核心都启动之前就开跑,就需要使用一个变量构造锁。
enum k_stage_t
{
K_BEFORE_BOOT = 0,
K_BOOT = 1,
K_BOOT_PERIP = 2,
K_BOOT_HARTS = 3,
K_MULTICORE = 4,
K_CLEARUP = 5
};
extern k_stage_t k_stage;然后在核心启动到 k_premain() 中增加:
while (k_stage != K_MULTICORE)
; // wait for the boot core to finish这将导致所有后启动的核心等待启动核心完成。
退出多核模式
退出多核模式之前,需要保证后启动核心正常停止,然后由启动核心清理现场。通过 k_after_main() 函数实现:
int k_after_main(int hartid, int main_ret)
{
if (hartid < 0) // Non boot hart
{
printf("Hart %i has returned with %d\n", ::hartid, main_ret);
k_hart_state[::hartid] = 3;
// printf("Failed to stop hart: %ld\n", SBIF::HSM::stopHart());
}
else
{
printf("\n> Waiting for other harts to return...\n");
int flag = 0;
do // a timeout can be added here
{
flag = 0;
for (int i = 0; i < 8; ++i)
{
if (i == hartid)
continue;
if (k_hart_state[i] == 1 || k_hart_state[i] == 2)
{
flag = 1;
break;
}
if (k_hart_state[i] == 3 || k_hart_state[i] == 0)
continue;
}
} while (flag);
k_stdout_switched = false;
k_stage = K_CLEARUP;
}
return main_ret; // pass to the lower
}newlib 的锁
虽然我们使用 TLS 提供了核心专用的 _reent,但是 IO 方面仍然不支持多核,需要加锁。这里要利用 newlib 的 retargetable locking,提供自己的实现。首先看 <sys/lock.h> 定义:
#if !defined(_RETARGETABLE_LOCKING)
typedef int _LOCK_T;
typedef int _LOCK_RECURSIVE_T;
#define __LOCK_INIT(class,lock) static int lock = 0;
#define __LOCK_INIT_RECURSIVE(class,lock) static int lock = 0;
#define __lock_init(lock) ((void) 0)
#define __lock_init_recursive(lock) ((void) 0)
#define __lock_close(lock) ((void) 0)
#define __lock_close_recursive(lock) ((void) 0)
#define __lock_acquire(lock) ((void) 0)
#define __lock_acquire_recursive(lock) ((void) 0)
#define __lock_try_acquire(lock) ((void) 0)
#define __lock_try_acquire_recursive(lock) ((void) 0)
#define __lock_release(lock) ((void) 0)
#define __lock_release_recursive(lock) ((void) 0)
#else
#ifdef __cplusplus
extern "C" {
#endif
struct __lock;
typedef struct __lock * _LOCK_T;
#define _LOCK_RECURSIVE_T _LOCK_T
#define __LOCK_INIT(class,lock) extern struct __lock __lock_ ## lock; \
class _LOCK_T lock = &__lock_ ## lock
#define __LOCK_INIT_RECURSIVE(class,lock) __LOCK_INIT(class,lock)
extern void __retarget_lock_init(_LOCK_T *lock);
#define __lock_init(lock) __retarget_lock_init(&lock)
extern void __retarget_lock_init_recursive(_LOCK_T *lock);
#define __lock_init_recursive(lock) __retarget_lock_init_recursive(&lock)
extern void __retarget_lock_close(_LOCK_T lock);
#define __lock_close(lock) __retarget_lock_close(lock)
extern void __retarget_lock_close_recursive(_LOCK_T lock);
#define __lock_close_recursive(lock) __retarget_lock_close_recursive(lock)
extern void __retarget_lock_acquire(_LOCK_T lock);
#define __lock_acquire(lock) __retarget_lock_acquire(lock)
extern void __retarget_lock_acquire_recursive(_LOCK_T lock);
#define __lock_acquire_recursive(lock) __retarget_lock_acquire_recursive(lock)
extern int __retarget_lock_try_acquire(_LOCK_T lock);
#define __lock_try_acquire(lock) __retarget_lock_try_acquire(lock)
extern int __retarget_lock_try_acquire_recursive(_LOCK_T lock);
#define __lock_try_acquire_recursive(lock) \
__retarget_lock_try_acquire_recursive(lock)
extern void __retarget_lock_release(_LOCK_T lock);
#define __lock_release(lock) __retarget_lock_release(lock)
extern void __retarget_lock_release_recursive(_LOCK_T lock);
#define __lock_release_recursive(lock) __retarget_lock_release_recursive(lock)
#ifdef __cplusplus
}
#endif
#endif /* !defined(_RETARGETABLE_LOCKING) */好了,你已经猜到要干嘛了,重新编译工具链,打开这个选项。
之后,利用 std:atomic 造一个锁结构:
struct __lock
{
std::atomic<int> owner = -1;
std::atomic<int> recursive_count = 0;
void lock(bool recursive = false)
{
if (k_stage != K_MULTICORE)
return;
// _write(0, (char*)"PLOCK\n",6);
if (recursive)
{
if (owner == hartid)
{
recursive_count++;
return;
}
}
int null_owner = -1; // helper for compare_exchange_weak
while (!owner.compare_exchange_weak(null_owner, hartid))
null_owner = -1;
recursive_count = 1;
// _write(0, (char *)"LOCK\n", 5);
}
void unlock(bool recursive = false)
{
if (k_stage != K_MULTICORE)
return;
if (recursive)
{
if (owner == hartid)
{
if (--recursive_count == 0)
owner = -1;
}
return;
}
if (owner == hartid)
owner = -1;
}
};由于声明中没有使用 __weak,所以我们要将整个编译单元的所有函数和变量全部覆盖,以通过编译,详情可以参见libc_hooks.cpp。
后记
通过这样的操作,多核环境就搭建好了,输出也没有冲突。当然,博客所示的代码还是比较少,详细实现还请参看仓库代码。
这一波用了 3 天,属实给我调试到麻了,各种冲突、异常,整个都是比较抽象的。不过,结果是好的,下一步,就可以折腾 CPU 的中断了。亲爱的读者,我们下期再会!